Distributed Data Parallel: How It Actually Works
*Part 1 of 4 — Distributed Training series. Start with the overview.*
1. Distributed Data Parallel: How It Actually Works (this post) — Scale throughput when the model fits on one GPU. 2. ZeRO and FSDP: Model Sharding — Fit models that don't fit, by sharding weights, gradients, and optimizer state. 3. Tensor Parallelism and Sequence Parallelism — Shard inside each layer; wins when interconnect is slow or a single layer is oversized. 4. Pipeline Parallelism: How It Actually Works — Shard across layers; the axis that cheaply spans nodes.
Distributed training solves two problems: the model doesn't fit on one GPU, or training is too slow. Distributed Data Parallel (DDP) is the answer to the second one.
A single GPU can only process tokens so fast. An A100 running a 4B model finetuning tops out around 3,000-4,000 tokens per second. A consumer RTX 4090 with a quantized model lands somewhere around 1,500-2,000. Doubling data or epochs doubles wall-clock time. The only way to bring it back down is to add more devices.
This is a throughput problem. A second GPU should cut the time roughly in half. The question is how.
The simplest answer is data parallelism. If the model already fits on one GPU, there's no need to split it across devices. Instead, each GPU holds a full copy of the model, processes a different slice of the data, and synchronizes gradients at the end of each step. PyTorch's implementation of data parallelism is Distributed Data Parallel (DDP). The API surface is small: a handful of lines on top of a standard training loop. But the difference between 1.9x scaling and 1.3x scaling comes from implementation details that PyTorch hides: how gradients are batched together for transfer, when communication overlaps with computation, and where common mistakes silently break both.
This post explains those mechanics: what happens inside dist.initprocessgroup, why the order gradients are sent matters, what the compute-communication overlap actually looks like on a timeline, and where it breaks. The code snippets are from a training script where we finetuned Qwen3-4B on AMI meeting transcripts from knkarthick/AMI with QLoRA.
---
The Setup
DDP runs one training process per GPU. Each process holds a full copy of the model and processes a different slice of the data. After every backward pass, the gradients from all processes are averaged and every copy applies the same update. The model stays in sync across GPUs without any central coordination.
That's the idea. The implementation details determine whether you get 1.9x or 1.3x. The code and numbers in this post come from the following setup:
| | | |---|---| | Model | Qwen3-4B (4-bit NF4 via BitsAndBytes) | | Method | QLoRA (r=16, alpha=32, all linear layers) | | Dataset | knkarthick/AMI (237 samples) | | GPUs | 2x RTX 4090 (PCIe, Vast.ai) | | Effective batch size | 16 (per-GPU=1, grad accum=8, 2 GPUs) | | Sequence length | 512 | | Optimizer | AdamW (lr=2e-4, cosine decay to 2e-5) | | Epochs | 3 |
---
Processes, Ranks, and World Size
DDP is process-based, not thread-based. Each GPU gets its own OS process with its own Python interpreter, its own CUDA context, and its own copy of every tensor. There is no shared memory between them. The only communication happens through NCCL.
Every process is assigned a rank: an integer from 0 to N−1, where N is the total number of GPUs. That total is the world size. The local rank is the rank within a single machine; on a single node they're identical, but on multi-node setups rank 4 might be local rank 0 on the second machine.
`
Single node, 2 GPUs: Two nodes, 2 GPUs each:
GPU 0 rank 0 localrank 0 Node 0: GPU 0 rank 0 localrank 0
GPU 1 rank 1 localrank 1 GPU 1 rank 1 localrank 1
worldsize = 2 Node 1: GPU 0 rank 2 localrank 0
GPU 1 rank 3 local_rank 1
world_size = 4
`
Rank 0 has a special role by convention: it's the only rank that prints logs, writes metrics, and saves checkpoints. Every rank has the same loss after AllReduce so any one of them could do it, but only one should.
torchrun handles the process spawning. It starts N processes, injects the environment variables each one needs (RANK, LOCALRANK, WORLDSIZE, MASTERADDR, MASTERPORT), and manages their lifecycle. The script never calls mp.spawn or subprocess directly.
`python
torchrun sets these before the script starts. just read them.
rank = int(os.environ["RANK"]) localrank = int(os.environ["LOCALRANK"]) worldsize = int(os.environ["WORLDSIZE"])`---
Process Group Initialization
Before any communication can happen, the processes need to find each other. dist.initprocessgroup(backend="nccl") is a collective call: it blocks until every rank in the world has called it, then opens the communication channels.
`python
def setup() -> int:
dist.initprocessgroup(backend="nccl")
localrank = int(os.environ["LOCALRANK"])
torch.cuda.setdevice(localrank)
return local_rank
`
torch.cuda.setdevice(localrank) binds this process to its GPU. Without it, every process defaults to GPU 0: all processes fight over the same device, memory gets double-allocated, and the run dies with a confusing error or silent corruption.
NCCL (NVIDIA Collective Communications Library) is the backend that handles the actual data movement between GPUs: over NVLink between cards on the same board, over PCIe between cards in the same machine, or over InfiniBand between machines. You don't configure any of this. NCCL detects the topology and picks the fastest available path.
At the end of training, dist.destroyprocessgroup() closes the channels. This should always run even if training crashes; a hung NCCL channel will keep all other processes waiting indefinitely.
`python
try:
train(local_rank)
finally:
dist.destroyprocessgroup() # runs even on crash
`
---
AllReduce
AllReduce is the operation that keeps every GPU synchronized. It takes one gradient tensor from each process, computes the element-wise mean across all of them, and hands the result back to every process simultaneously.
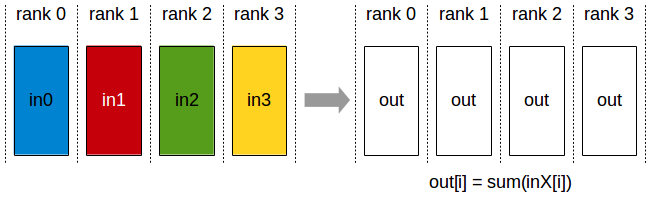
!AllReduce: each rank starts with its own input buffer and ends with the same reduced output across all ranks *Each rank contributes its local data. After AllReduce, every rank holds the same reduced result. (Source: NVIDIA NCCL docs)*
{kind=link}
`
Before AllReduce: After AllReduce (mean):
rank 0: [1.0, 2.0, 3.0] rank 0: [2.0, 4.0, 6.0]
rank 1: [2.0, 4.0, 6.0] -----> rank 1: [2.0, 4.0, 6.0]
rank 2: [3.0, 6.0, 9.0] rank 2: [2.0, 4.0, 6.0]
`
Every process ends up with the same value, applies the same optimizer update, and the model copies stay in sync. No parameter broadcasting needed after the update.
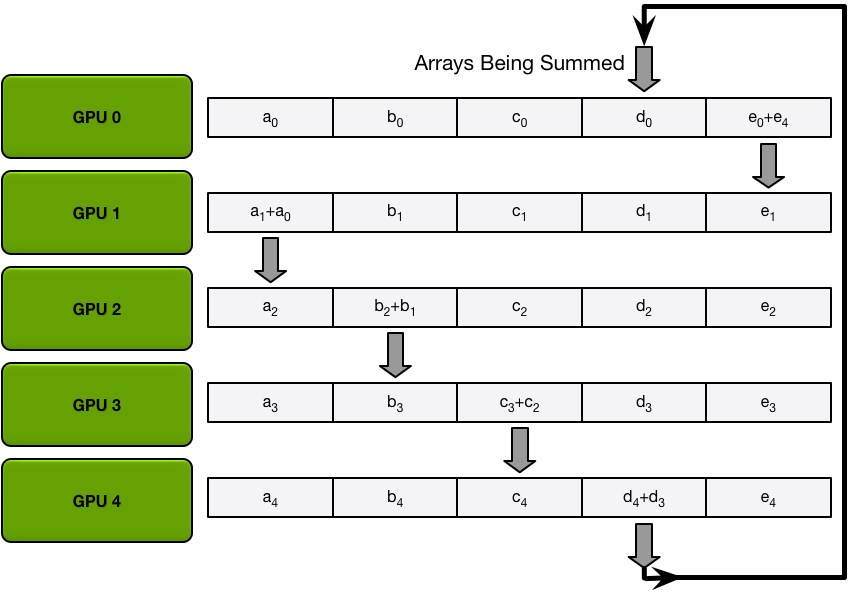
NCCL implements AllReduce as a ReduceScatter followed by an AllGather. These two operations become the central primitives in → FSDP, where they run per layer instead of once per step.
!Ring AllReduce: Scatter-Reduce phase where GPUs pass partial sums around the ring *Ring AllReduce: GPUs pass partial sums around the ring. Total data transferred per GPU: 2(N-1)/N x tensor_size, approaching 2x regardless of GPU count. (Source: Andrew Gibiansky)*
{kind=link}
---
Gradient Buckets and the Compute-Communication Overlap
AllReduce is not free. For a model with hundreds of parameter tensors, firing off a separate AllReduce for each one would generate enormous overhead from round-trip latency alone. DDP solves this by packing gradients into buckets and launching one AllReduce per bucket.
The key detail is bucket ordering. DDP fills buckets in reverse layer order: last layer first. This is intentional. During backward, gradients are computed from the output layer toward the input. The last layer's gradients are ready first. By filling buckets from the end of the network forward, DDP can launch AllReduce on those first buckets while the earlier layers are still running backward.
Here's what that looks like on a timeline:
`
Single GPU:
Forward -----> Backward (layer N ... layer 1) -----> Optimizer step
Naive multi-GPU (no overlap): Forward -----> Backward -----> AllReduce -----> Optimizer step (slower than single GPU due to AllReduce on top)
DDP (with overlap):
Forward -----> Backward [layer N] -> [AllReduce bucket 1 starts]
[layer N-1] [bucket 1 done]
[layer N-2] -> [AllReduce bucket 2 starts]
...
[layer 1] [bucket K done]
-----> Optimizer step (AllReduce already mostly done)
`
In the well-overlapped case, by the time the last layer finishes backward, most of the gradient communication is already complete. The optimizer step starts almost immediately. This is what produces near-linear throughput scaling.
The overlap is implemented through autograd hooks. When DDP wraps the model, it registers an AccumulateGrad hook on every parameter. When a parameter's gradient is computed during backward, the hook fires: it marks that parameter's gradient as ready, and if its bucket is now full, launches the AllReduce for that bucket. The hook runs in the same CUDA stream as the backward kernel, so communication and computation can run concurrently on the GPU.
Several common mistakes break these hooks silently (more on that below).
---
DistributedSampler
Without intervention, every process loads the dataset using the same default indices. Every GPU runs forward and backward on identical batches. AllReduce averages identical gradients and produces identical results to what a single GPU would have produced. Two GPUs doing the work of one.
DistributedSampler fixes this by partitioning the dataset across ranks. It divides the index list into N equal-sized, non-overlapping shards and gives each rank its own shard. Each GPU sees a different portion of the data per epoch.
`python
sampler = DistributedSampler(dataset, numreplicas=worldsize, rank=rank, shuffle=True)
loader = DataLoader(
dataset,
batchsize=BATCHSIZE,
sampler=sampler, # replaces shuffle=True
...
)
`
One required call that's easy to forget: sampler.set_epoch(epoch) at the start of each epoch.
`python
for epoch in range(EPOCHS):
sampler.set_epoch(epoch) # reseed shuffle for this epoch
...
`
The sampler uses the epoch number as a seed for shuffling. Without this call, every epoch shuffles identically: rank 0 always sees the same 118 samples in the same order across all 3 epochs, which is no better than not shuffling at all.
With 237 AMI samples and 2 GPUs, DistributedSampler with the default droplast=False duplicates one sample to make the split even, so the effective dataset is 238 and each rank sees 119 samples per epoch. (With droplast=True it would round down instead, each rank seeing 118 and the 237th sample dropped.) Effective batch size is BATCHSIZE * worldsize * GRAD_ACCUM = 1 * 2 * 8 = 16, matching the single-GPU run for a fair comparison.
This is a detail that's easy to miss when moving from single-GPU to DDP. The single-GPU run used GRADACCUM = 16 for an effective batch size of 1 * 16 = 16. Adding a second GPU doubles the number of gradient contributions per step, so GRADACCUM must be halved to 8 to keep the effective batch size the same. Without this adjustment, the effective batch size doubles to 32, the learning rate is effectively too high for the batch size, and the loss curves between single-GPU and DDP are no longer comparable.
---
DDP Wrapping
After the model is loaded and moved to its GPU, wrapping it is one line:
`python
model = DDP(model, deviceids=[localrank], findunusedparameters=False)
`
deviceids=[localrank] tells DDP which GPU this process owns. Without it, DDP has to scan all available devices on each step.
findunusedparameters=False tells DDP not to scan the computation graph after every forward pass looking for parameters that weren't used. This scan is a blocking operation: it has to complete before backward starts, which delays bucket filling and cuts into the overlap. The option exists for models with conditional forward paths where some parameters might legitimately be skipped. For a standard model where every parameter is used on every step, it adds overhead with no benefit.
After wrapping, the underlying model is accessible via model.module. This matters at save time:
`python
saves the DDP wrapper including sync state, not what you want
model.savepretrained(savepath) # wrongsaves the actual model weights
model.module.savepretrained(savepath) # correct`---
DDP + QLoRA: What's Actually Being AllReduced
This combination has an interesting property worth understanding. QLoRA freezes the base model weights in 4-bit and trains only the LoRA adapters, which are roughly 1% of total parameters. The frozen base weights have requires_grad=False. DDP only AllReduces parameters that have gradients.
In practice: the 4-bit base model weights are never touched by AllReduce. The only tensors crossing the wire are the LoRA adapter gradients, which amount to roughly 40 MB per step. For comparison, a full BF16 AllReduce on a 4B model's gradients (8 GB) would move roughly 2(N-1)/N * 8 GB over the network — about 8 GB per GPU at N=2 and up to ~16 GB per GPU for large N. Two orders of magnitude more than the QLoRA case.
This is why findunusedparameters=False is safe here. Every LoRA parameter participates in every forward pass. The frozen parameters don't need to be checked because they have no gradients.
There's a subtlety with gradient checkpointing in this setup. QLoRA freezes the base model, so the forward pass through those frozen layers produces activations with requiresgrad=False. Gradient checkpointing needs to recompute activations during backward, and it can't do that if the activations were detached from the computation graph. The fix is model.enableinputrequiregrads(), which forces the input tensors to carry gradient tracking through the frozen layers so checkpointing can reconstruct the graph on the backward pass.
---
The device_map="auto" Trap
This is a common source of silent failure when moving from single GPU to DDP. Loading with devicemap="auto" distributes layers across all visible GPUs in pipeline fashion: GPU 0 holds layers 0-15, GPU 1 holds layers 16-31, and so on. This is naive pipeline parallelism, not data parallelism. DDP assumes each process owns exactly one GPU and holds the complete model on it. These two assumptions conflict directly: devicemap="auto" spreads one model across all GPUs, DDP expects one full model per GPU.
The fix is devicemap={"": localrank}: place the entire model on this process's assigned GPU.
`python
breaks DDP: splits the model across all GPUs in pipeline fashion
model = AutoModelForCausalLM.frompretrained(MODELID, device_map="auto", ...)correct: each process loads the full model onto its own GPU
model = AutoModelForCausalLM.frompretrained(MODELID, devicemap={"": localrank}, ...)`The failure mode is insidious. With device_map="auto" and 2 GPUs, each torchrun process sees both GPUs and spreads the model across them. Both processes end up with interleaved layer assignments on both devices, NCCL operations target the wrong tensors, and training either hangs or produces garbage gradients without a clear error message.
---
Gradient Accumulation and no_sync()
Gradient accumulation runs multiple forward-backward passes before calling the optimizer, simulating a larger effective batch size. With DDP, there's a trap: AllReduce fires on every loss.backward() call by default.
If you accumulate over 8 steps without intervention, you pay for 8 AllReduces when you only need 1. The gradients from the intermediate steps are discarded anyway (they get summed into .grad locally), so those 7 extra AllReduces are pure waste.
model.no_sync() is a context manager that suppresses AllReduce on backward. Use it on all accumulation steps except the last:
`python
isaccumulating = (step + 1) % GRADACCUM != 0
synccontext = model.nosync() if is_accumulating else contextlib.nullcontext()
with sync_context: with torch.autocast(device_type="cuda", dtype=torch.bfloat16): outputs = model(inputids=inputids, labels=labels) loss = outputs.loss / GRAD_ACCUM loss.backward()
if not is_accumulating:
torch.nn.utils.clipgradnorm(model.parameters(), MAXGRAD_NORM)
optimizer.step()
scheduler.step()
optimizer.zerograd(setto_none=True)
`
Mechanically, no_sync() temporarily disables the AccumulateGrad hooks. Backward runs normally and gradients accumulate in .grad, but no AllReduce is launched. On the final accumulation step, the context is nullcontext(), the hooks are active again, and AllReduce fires exactly once with the accumulated gradient.
---
The Full Script
The complete training script is on GitHub. The diff from the single-GPU version is small:
| Single GPU | DDP |
|---|---|
| No process group | dist.initprocessgroup("nccl") |
| devicemap="auto" | devicemap={"": local_rank} |
| DataLoader(shuffle=True) | DataLoader(sampler=DistributedSampler(...)) |
| Plain model | DDP(model, deviceids=[localrank]) |
| Always print/log/save | Guard with if rank == 0 |
| model.savepretrained() | model.module.savepretrained() |
| sampler.set_epoch() not needed | Required at start of each epoch |
| No nosync() | nosync() on accumulation steps |
Run it:
`bash
torchrun --nprocpernode=2 experiments/ddp-ft/train.py
`
---
What Breaks the Overlap
The compute-communication overlap is what makes DDP fast. It relies on the AccumulateGrad hooks firing at the right moments during backward. Several mistakes break these hooks without raising an error.
findunusedparameters=True when you don't need it
The graph scan runs after forward completes, delaying the start of backward. Bucket filling is delayed, AllReduce launches late, and the overlap disappears. Use this only when the model has genuine conditional paths that skip parameters.
Missing no_sync() with gradient accumulation
Without it, DDP fires AllReduce on every backward call, not just the last. Communication scales with your accumulation factor. The fix is shown above.
Gradient checkpointing with use_reentrant=True
Gradient checkpointing saves memory by discarding activations during the forward pass and recomputing them during backward. The default usereentrant=True implementation uses torch.autograd.checkpoint, which re-enters the autograd graph in a way that can interfere with DDP's AccumulateGrad hooks. The hooks may not fire at the expected bucket boundaries, breaking the overlap. Using usereentrant=False avoids this by running the recomputation through a different code path that preserves the hook registration. The training script sets this explicitly:
`python
model.gradientcheckpointingenable(gradientcheckpointingkwargs={"use_reentrant": False})
`
DataLoader workers starving the GPU
If the CPU can't produce batches fast enough, the GPU idles between steps regardless of how well the overlap is configured. The overlap exists within a step; stalls between steps are a separate problem. If nvidia-smi shows GPU utilization bouncing between 60-80% instead of holding near 100%, num_workers is too low or preprocessing is too slow.
---
Expected Results
With 2 GPUs on the same node, the expected results look like this:
| Metric | Single GPU | DDP (2x GPU) | |---|---|---| | Tokens/sec | ~1,650 | ~3,000-3,200 | | Step time | ~7.3s | ~4-5s | | Peak VRAM/GPU | 5.58 GB | ~6-7 GB | | Effective batch | 16 | 16 |
Why ~1.9x and not 2x. Perfect scaling would double throughput. The gap comes from AllReduce overhead that is not fully hidden by the overlap. On every sync step, the LoRA adapter gradients (~40 MB) must traverse the interconnect. With PCIe (our setup), the link runs at ~25 GB/s effective bidirectional, so the AllReduce itself takes under 2 ms, but NCCL kernel launch latency, Python dispatch, and the tail of the last gradient bucket add up. On NVLink (600+ GB/s), this overhead nearly vanishes and scaling lands at 1.95x or higher. On multi node setups over Ethernet, it can drop to 1.5-1.7x because the AllReduce latency is no longer hidden within the backward pass.
Why VRAM per GPU is higher. DDP allocates additional memory that single GPU training does not need. The gradient communication buffers (one per bucket, sized to hold packed gradients for AllReduce) add a fixed overhead. DDP also maintains internal bookkeeping: per parameter synchronization flags, the bucket metadata structures, and a copy of the flattened gradient buffer for the AllReduce output. For QLoRA where only ~1% of parameters are trainable, this overhead is small (hundreds of MB). For full finetuning, the gradient buffers alone equal the size of the gradient tensor (2P bytes in BF16), which can be significant.
Loss curves. With the same effective batch size (16), the same learning rate schedule, and the same data (just partitioned differently), the DDP loss curve should track the single GPU curve closely. Small divergences are expected from the different data ordering across ranks and from floating point noncommutativity in AllReduce (the sum of gradients from 2 GPUs is not bit identical to the sum from 1 GPU with double the accumulation steps). These differences are well within noise and do not affect final model quality.
---
When DDP Is Not the Right Tool
DDP handles the throughput problem when the model fits on each GPU. When it doesn't (when weights, gradients, and optimizer states together exceed device memory), DDP offers no relief. Adding more GPUs under DDP doesn't change the per-GPU memory footprint.
That's the problem → FSDP solves. Instead of replicating the model across GPUs, FSDP shards weights, gradients, and optimizer states so no single GPU holds a complete copy. Memory per GPU drops proportionally with the number of GPUs. The training loop structure is nearly identical to DDP: the concepts covered here (AllReduce, gradient buckets, no_sync(), DistributedSampler) carry over directly.
When the model fits on each GPU but you want to split the computation *inside* each layer rather than replicate it, → Tensor Parallelism is the other option. And when even sharding can't fit the model (100B+ parameters), → Pipeline Parallelism partitions layers across GPUs so each device only holds a slice of the network.